Цели поисковых систем очень простые – удовлетворить потребности пользователей. Сначала проанализировать его текстовые или голосовые запросы, понять, что он хочет получить, а затем подобрать максимально соответствующий запросу документ. В первую очередь важны тексты, поскольку поисковая система только с помощью их может понять, что же находится в документе. Наша задача составить такой заголовок, чтобы он максимально раскрывал содержание текста и показывал, каким запросам релевантен этот документ.
Одну и ту же информацию пользователи могут искать по разным запросам (например, подставка под обувь – этажерка для обуви) и наша задача сделать так, чтобы поисковая система понимала это и работала со всеми документами, которые содержат нужные данные. Текстовый фактор - один из важнейших факторов для поисковых систем. С помощью модели дистрибутивной семантики и векторного представления поисковые системы могут анализировать запросы и находить наиболее подходящие ответы для пользователей. Помимо LSI поисковые системы используют:
- модель векторных пространств;
- тематическое моделирование.
LSI, или латентно-семантический анализ – это метод обработки информации, где анализируется взаимосвязь между документами и терминами в этих документах. Данный анализ позволяет находить связи между терминами.
ЛСА фразы – это те фразы, которые чаще встречаются вместе с заданными нами терминами (например, вместе со словом «кошка» часто встречаются слова «кот», «собака», «животное» и т.д.).
Наша задача найти эти фразы, определить наиболее весомые и использовать в тексте, чтобы разнообразить его, сделать его более естественным, и чтобы он получал больше поискового трафика.
Как же найти связи между словами?
Без искусственного интеллекта и нейронных сетей здесь, конечно, не обойтись. Базовым инструментов является Word2vec, разработанный Google. Однако он не выдает сразу нужные слова, его необходимо обучить. Данная программа достаточно сложная в использовании, поэтому мы используем другие инструменты.
LSI-фразы можно искать:
- анализируя спрос – запросы, которые вводят пользователи либо то, что нам рекомендует поисковая система;
- анализируя текст - на сайтах или на выдаче, можно уже анализировать семантические связи;
- комплексный подход – анализируется все.
Инструменты для анализа спроса
Первый инструмент для анализа спроса – это поисковые подсказки. Если в одной поисковой системе вам недостаточно фраз, то вы можете использовать в ней другие регионы, таким образом запросы будут меняться. Например, мы анализируем в Яндексе запрос «полка для обуви», ПС нам сразу же предлагает дополнительные слова, которые не подсвечены.
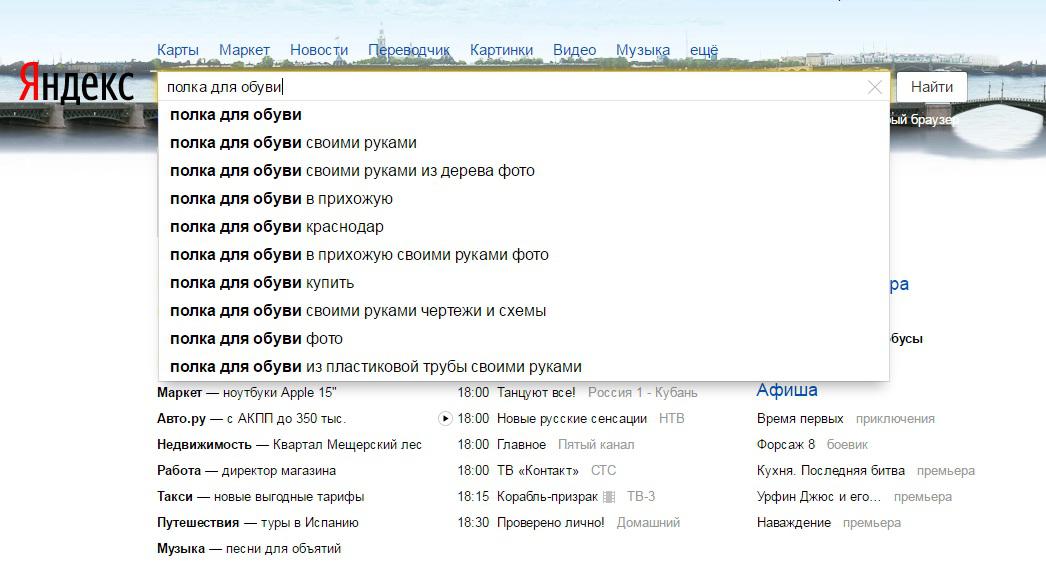
Эти слова можно добавить в ЛСА-ядро, которое далее мы будем чистить, оставляя наиболее удачные запросы. Чтобы не делать это вручную, можно использовать сервис Serpstat, однако, там будет много лишних подсказок.
Следующий метод - рекомендация в поиске. Если ввести запрос в ПС и опуститься вниз, то мы увидим, что с этим чаще всего ищут. В данном блоке нам интересны слова, которые выделены жирным. Все рекомендации необходимо записать в таблицу вместе с подсказками.
Далее мы отфильтруем то, что записали. Нужно учесть, что спрос отражает либо сезонность, либо региональность (например, Google предложил название местного магазина). Региональные элементы спроса нам не понадобятся, эти слова интересны при условии, что вы их продвигаете.
Последний инструмент для анализа спроса, который мы будет использовать - это Wordstat. Слева будет информация, которую мы уже получили через рекомендации и подсказки, нас интересует правая колонка, добавляем слова из нее в наше семантическое ядро.
Инструменты для анализа текстов
Тексты можно анализировать на выдаче (сниппеты) или на самом сайте, у каждого из этих методов есть свои недостатки, если сниппеты слишком короткие, то в полных текстах может быть много лишней информации.
Метод строительства частотного словаря – это определение тех слов, которые чаще всего встречаются с нашим запросом.
Идеальным методом будет учет отдаленности слов от ключевого, чем ближе слово находится к ключевому, тем больше его весомость. При строительстве словаря в первую очередь нужно учитывать вес слова.
Первый из доступных инструментов для поиск а ЛСА-фраз - парсинг подсветок (Арсенкин). Нужно ввести запрос, один или несколько и выставить ТОП-20, поскольку в ТОП-10 будет мало информации. Нам нужна последняя таблица со словами, задающими тематику.
Следующий инструмент «Пиксель Тулс» - выбираем «ТЗ для копирайтинга» и запускаем на обработку.
Для анализа теста рекомендуется использовать сервис TextAnalyzer, можно копировать несколько текстов из выдачи и посмотреть на результат. Однако более ценную информацию вы получите, если скопируете целый текст, но в этом случае будет много лишних слов.
Модуль Акварель-генератор – инструмент, подбирающий наиболее близкие слова к ключевому запросу, который нас интересует. Минус данной программы в том, что она подбирает слишком много слов, которые приходится группировать вручную.
Как работать с созданной таблицей?
Для начала следует отсортировать слова, которые использовались в максимальном числе источников, а также исключить, использованные только в одном. Работаем только с оставшимися словами.
Чем длиннее текст, тем больше LSI-фраз вы должны иметь в околосемантическом ядре. Для короткого текста достаточно 20 – 30 слов. В Title рекомендуется использовать около 5 LSI-слов. При составлении объемной статьи используйте хотя бы 100 слов из LSI-ядра на 1000 слов общего текста. Старайтесь в каждом предложении использовать слова из семантического или околосемантического ядра. Польза по LSI должна быть не меньше 10%.